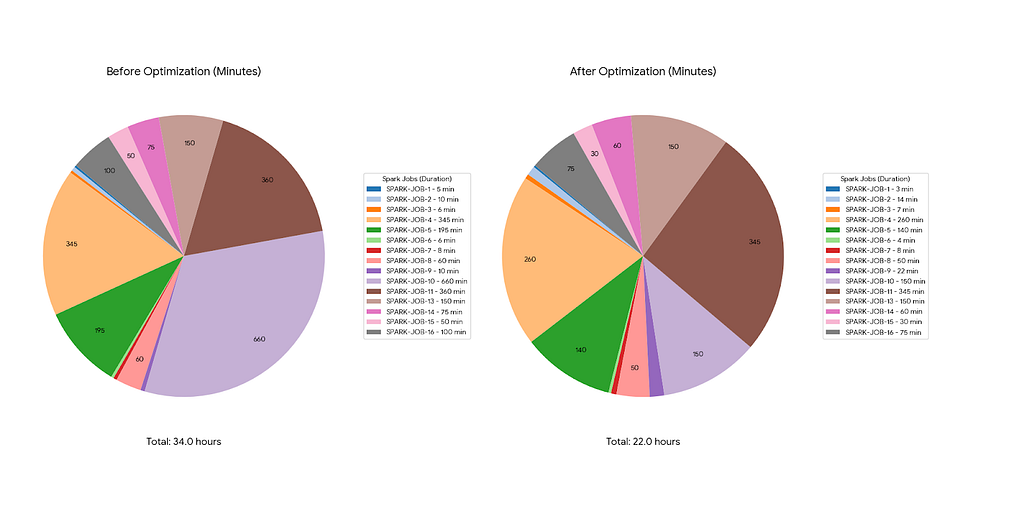
Context Ambitious goal and the scope of the problem We were chasing a critical, futuristic business requirement for our big data pipelines achieving “1-day planning,” defined as a total execution window of 24 hours or less . The entire process is extensive, processing a 7TB data volume each cycle across 19 distinct plans (16 Spark pipelines and 3 Data Science…
#apache-spark
3 posts
9 Dec 2025
6 Oct 2025

As a data engineer, I used to see metrics as just numbers on a dashboard — until I realized they’re the lens through which customers view and run their operations. In customer support, for example, agent productivity metrics aren’t just figures, they’re actionable insights that drive efficiency, shape staffing decisions, and directly impact customer satisfaction. These aren’t just charts —…
21 Feb 2024

Leveraging Spark 3 and NVIDIA’s GPUs to Reduce Cloud Cost by up to 70% for Big Data Pipelines
PaypalBy Ilay Chen and Tomer Akirav At PayPal, hundreds of thousands of Apache Spark jobs run on an hourly basis, processing petabytes of data and requiring a high volume of resources. To handle the growth of machine learning solutions, PayPal requires scalable environments, cost awareness and constant innovation. This blog explains how Apache Spark 3 and GPUs can help enterprises…