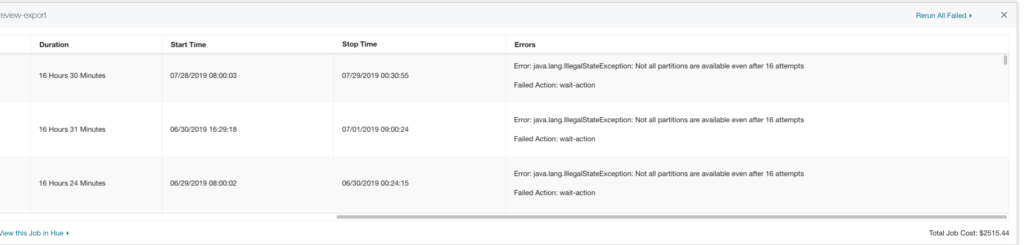
Parth Shah and Thai Bui Overview One of the reasons why Hadoop jobs are hard to operate is their inability to provide clear, actionable error diagnostic messages for users. This stems from the fact that Hadoop consists of many interrelated components. When a component fails or behaves poorly, the failure will be cascaded to its […]
#hadoop
6 posts
7 Aug 2019
6 Jan 2016
I love really Amazon EMR. Over the years it’s grown from being “Hadoop on-demand” to a full-fledged cluster management system for running OSS big-data apps (Hadoop MR of course, but also Spark, Hue, Hive, Pig, Oozie and more). While Hadoop out of the box supports reading from S3, EMR has a proprietary implementation called EMRFS that has some nice features.…
20 Dec 2015
My previous post showed a very simple Scalding workflow. Apache Flink is a real time streaming framework that’s very promising. It also supports running Cascading workflows with very little modification. Surely there must be some way to run a Scalding job on top of Flink? Turns out… YES! In a nutshell Here are the high-level things we need to solve…
I’ve been using Scalding for the last few years and really love how simple it makes writing scalalbe data processing jobs. I think many of the issues beginners have with Scalding relate to project setup. I hope this post simplifies things for people so they can started with less hassle. Building your project with SBT The official getting started guide…
28 Sept 2014
It’s occasionally useful when writing map/reduce jobs to get a hold of the current filename that’s being processed. There’s a few ways to do this, depending on the version of Spark that you’re using. Spark 1.1.0 introduced a new method on HadoopRDD that makes this super easy: import org.apache.hadoop.io.LongWritable import org.apache.hadoop.io.Text import org.apache.hadoop.mapred.{FileSplit, TextInputFormat} import org.apache.spark.rdd.HadoopRDD // Create the text…
2 Jan 2014
At MediaMath we’re big users of Elastic MapReduce. EMR’s incredible flexibility makes it a great fit for our analytics jobs. An extremely important best practice for any analytics project is to ensure your local dev and test environments match your production environment as much as possible. This eliminates the nasty surprise of launching a job that takes hours only to…