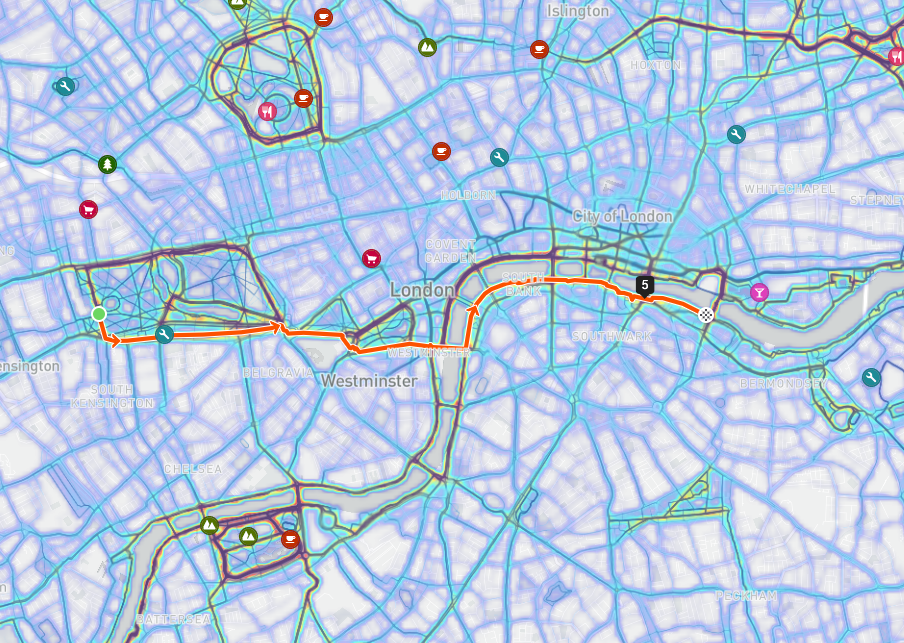
Much of our heatmaps are built on batch data outputs stored in Rain At Strava, we love maps — some of our most loved features are nestled on map surfaces. My team, the Geo team, is focused on building and improving these products. On the Geo and Metro teams, we tend to work with large datasets: aggregations of open source…
#spark
4 posts
24 Jan 2025
29 Oct 2021
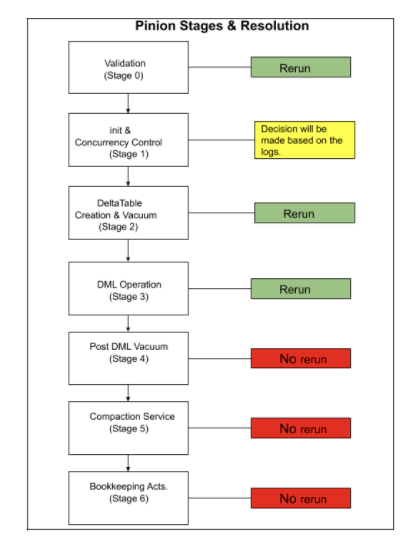
Pinion — The Load Framework Part-2 This post is the 2nd part of the “Pinion — The Load Framework” series. In case you have not read the 1st post, you can read it here . In this post, we are going to cover the following topics. How does Pinion use Delta Lake for SCD operations? Small file problem with Delta…
28 Sept 2014
It’s occasionally useful when writing map/reduce jobs to get a hold of the current filename that’s being processed. There’s a few ways to do this, depending on the version of Spark that you’re using. Spark 1.1.0 introduced a new method on HadoopRDD that makes this super easy: import org.apache.hadoop.io.LongWritable import org.apache.hadoop.io.Text import org.apache.hadoop.mapred.{FileSplit, TextInputFormat} import org.apache.spark.rdd.HadoopRDD // Create the text…
7 Aug 2014
Strange bedfellows: how a web-tier validation framework enables strongly typed, big data pipelines
Ian HummelThe other day I was talking with a colleague about data validation and the Play web framework came up. Play has a nice API for validating HTML form and JSON submissions. This works great when you’re processing small amounts of data from the web-tier of your application. But could that same tech benefit a Big Data team working on a…