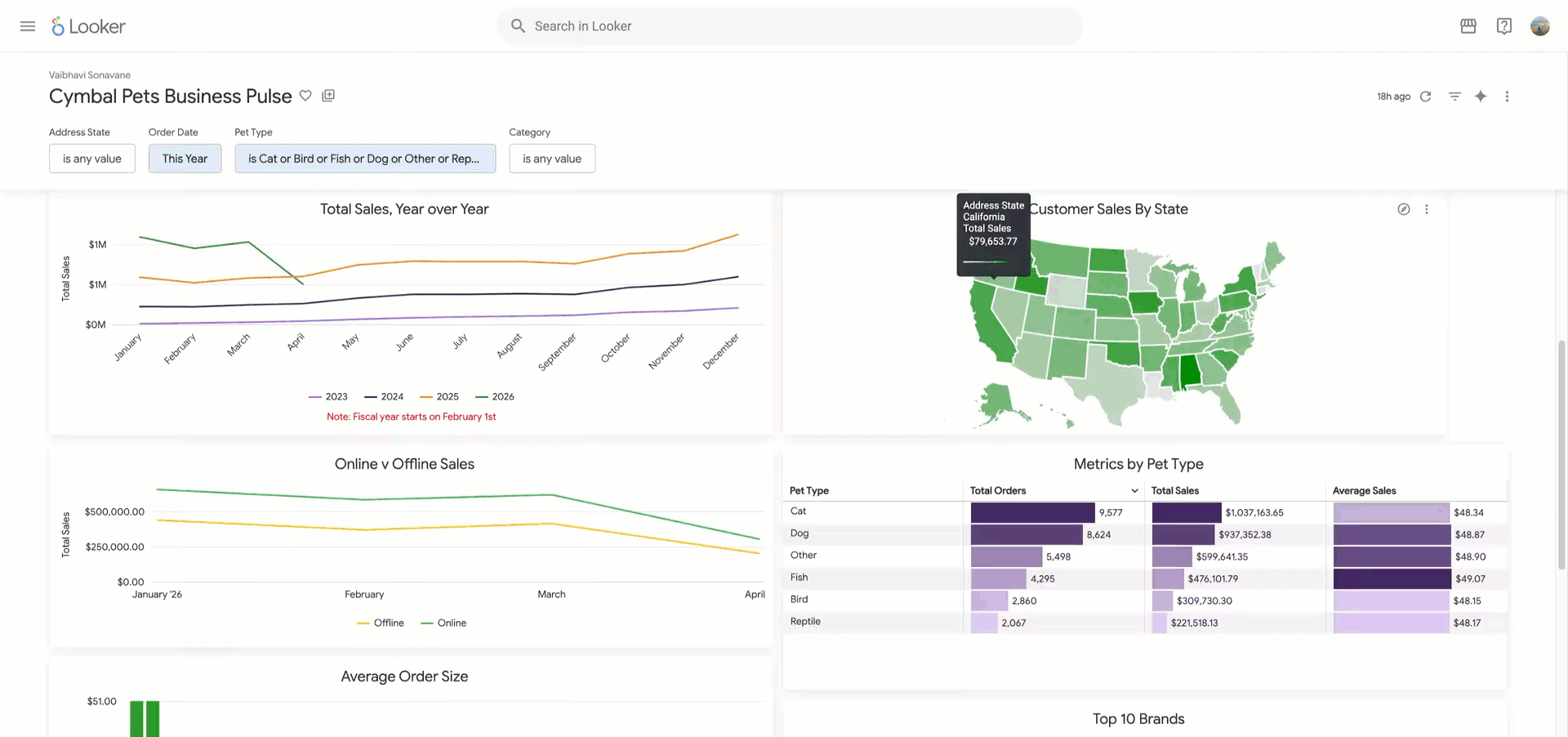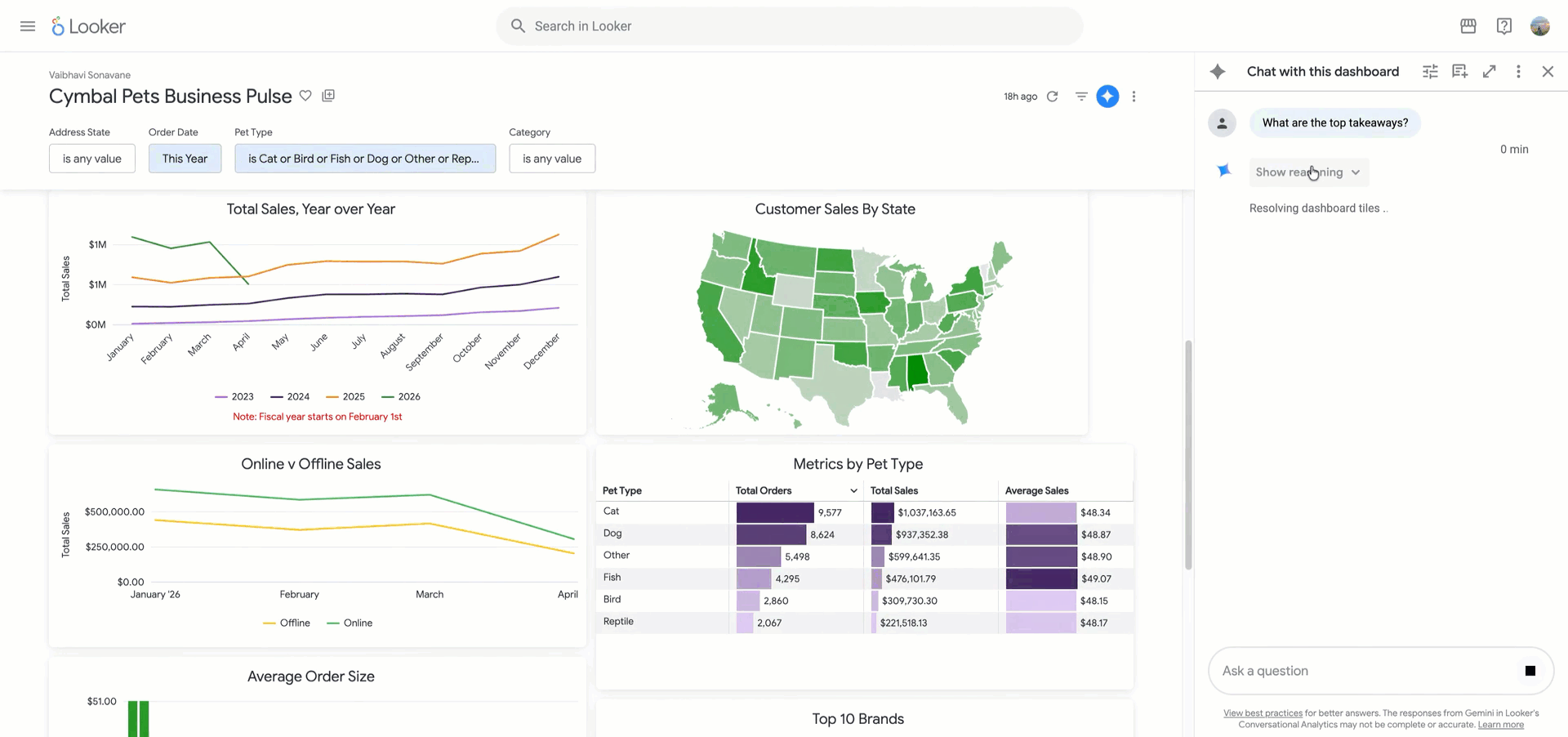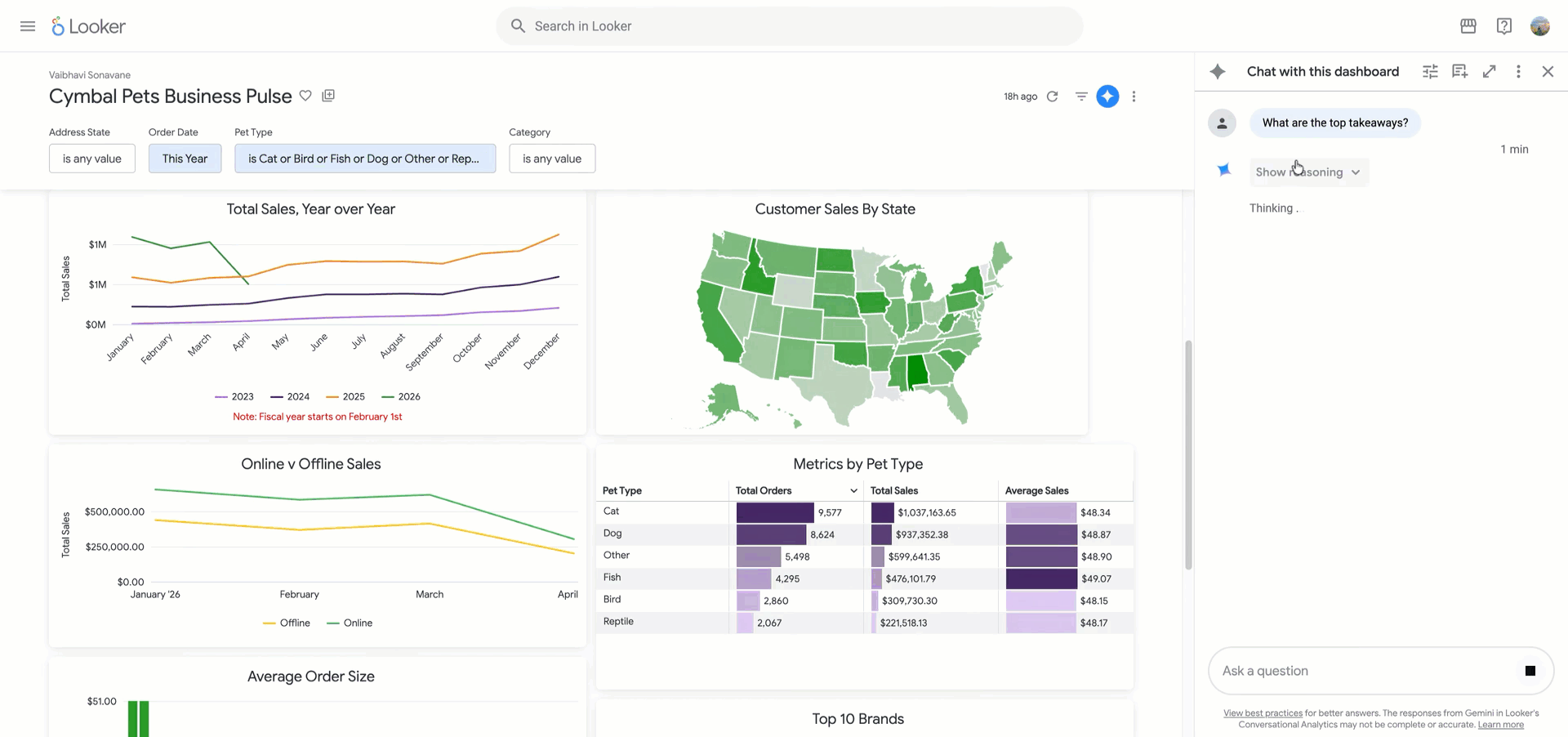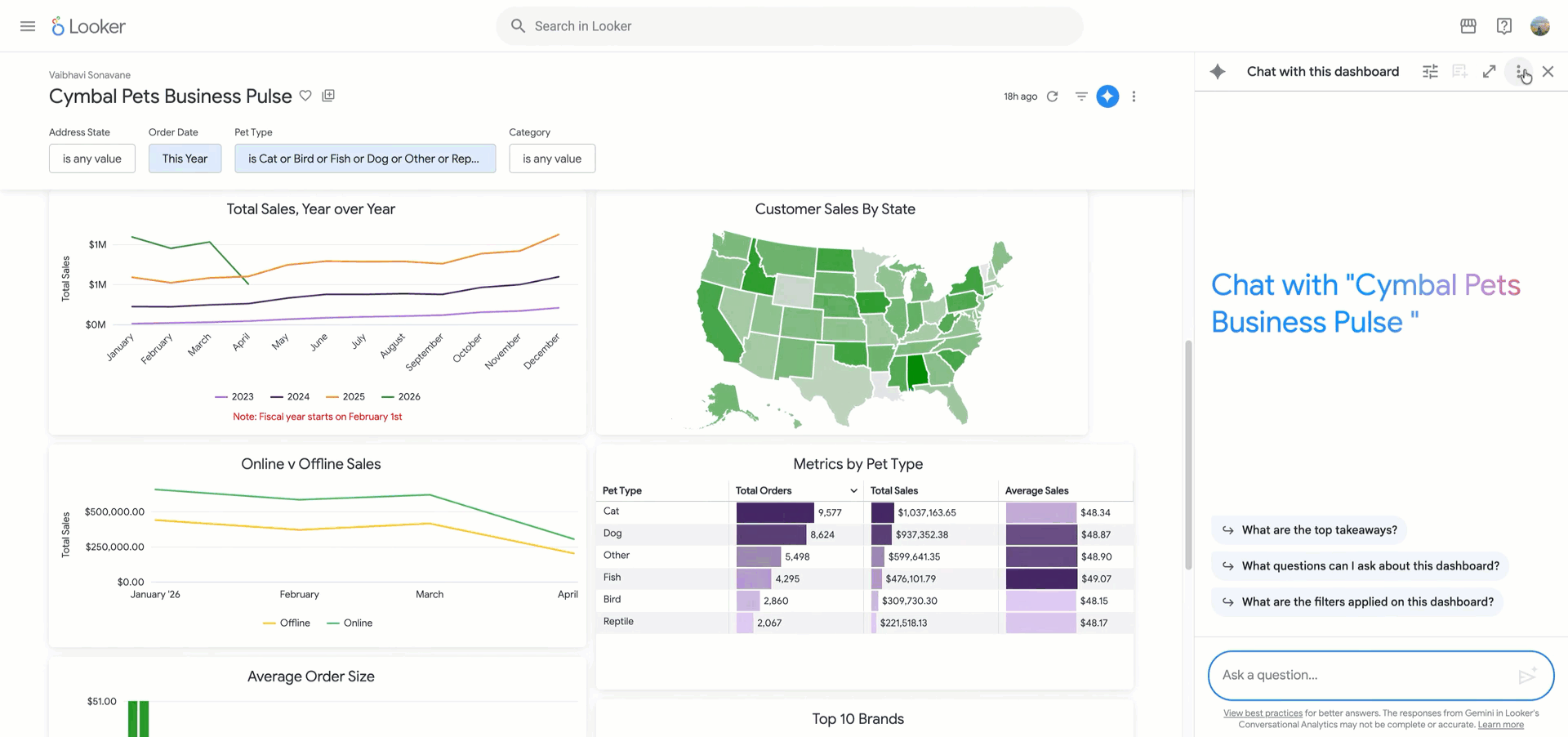
Dashboards have long served as a primary way for organizations to extract insights from data, but they can fall short in agile environments: Dashboards aren’t interactive and don’t allow you to ask follow-up questions. This forces users to step outside their workflows or turn to data analysts to get the answers they need. Today, we are introducing Looker dashboard agents…
#data analytics
27 posts
Yesterday
10 Jun

From foundational ETL and analytics to the frontier of generative AI, Apache Spark serves as the architectural backbone for global data processing. However, as data volumes scale, the trade-off between performance and infrastructure costs can be a limiting factor for growth. In the agentic era, where autonomous agents can trigger thousands of concurrent, multi-hop queries, this performance bottleneck directly dictates…
8 Jun

Modernizing Healthcare: How Alcidion achieved greater stability and performance with AlloyDB
Google CloudIn clinical informatics, every second counts. For Alcidion, a global leader in smart health solutions, the mission is simple but critical: use technology to reduce cognitive load for clinicians and present the right information at the right time to save lives. Whether it’s managing patient flow in an emergency department or ensuring a patient is in the correct ward to…
4 Jun

At Google Cloud, our goal is to let you run large-scale analytical and data science workloads with maximum efficiency so you can process big data pipelines, machine learning, and ETL tasks. We recently announced that the Dataproc service is now Managed Service for Apache Spark, reflecting our deep integration with the Agentic Data Cloud. To support the diverse architectural needs…

June 1 - June 5 Beyond the Query: Powering AI Agents with Bigtable, Firestore & Memorystore Discover the latest advancements in Google Cloud's NoSQL Database portfolio, including Bigtable, Firestore, and Memorystore. This series is designed for a broad audience: whether you are exploring these databases for the first time or are an existing user looking to leverage the new capabilities…
3 Jun
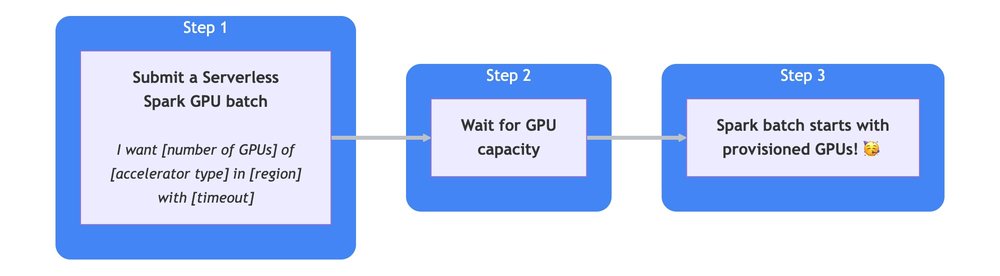
Whether you use it for data preparation, real-time interactive queries, AI model training, or something entirely different, running Apache Spark at scale is demanding — you shouldn’t have to manage the underlying infrastructure too. Late last year, we announced the general availability (GA) of our serverless Managed Service for Apache Spark runtime version 3.0, prioritizing speed, simplicity, and reliability. Since…
2 Jun
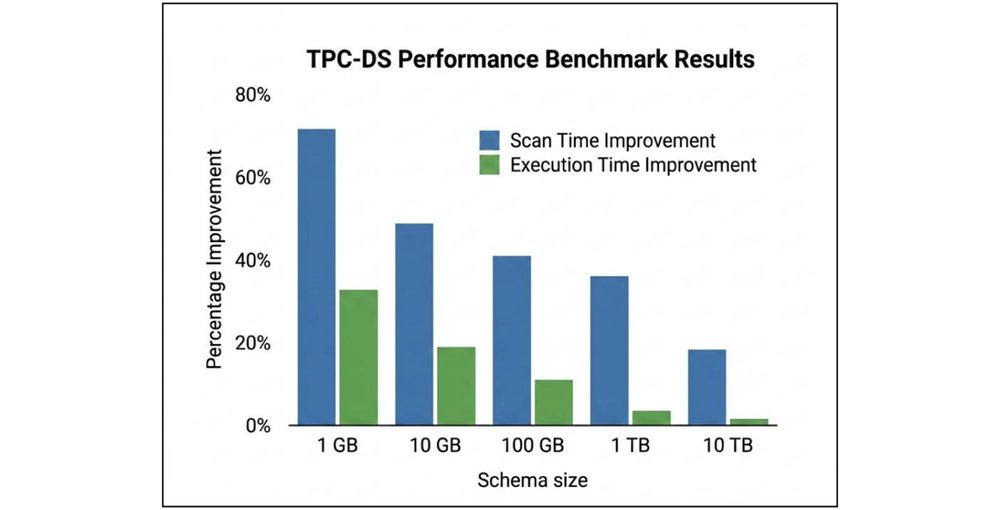
Many data engineers spend significant time managing compatibility and getting best performance across multiple analytics engines. To help solve this pain point, we are excited to announce gcs-analytics-core, a new open-source Java library designed to centralize and accelerate analytics optimizations for Google Cloud Storage (GCS). With this, you get the flexibility to select your preferred analytics engine while achieving high…
20 Jun 2025

How We Built Canva's IMPACT App with Streamlit in Snowflake
27 May 2025
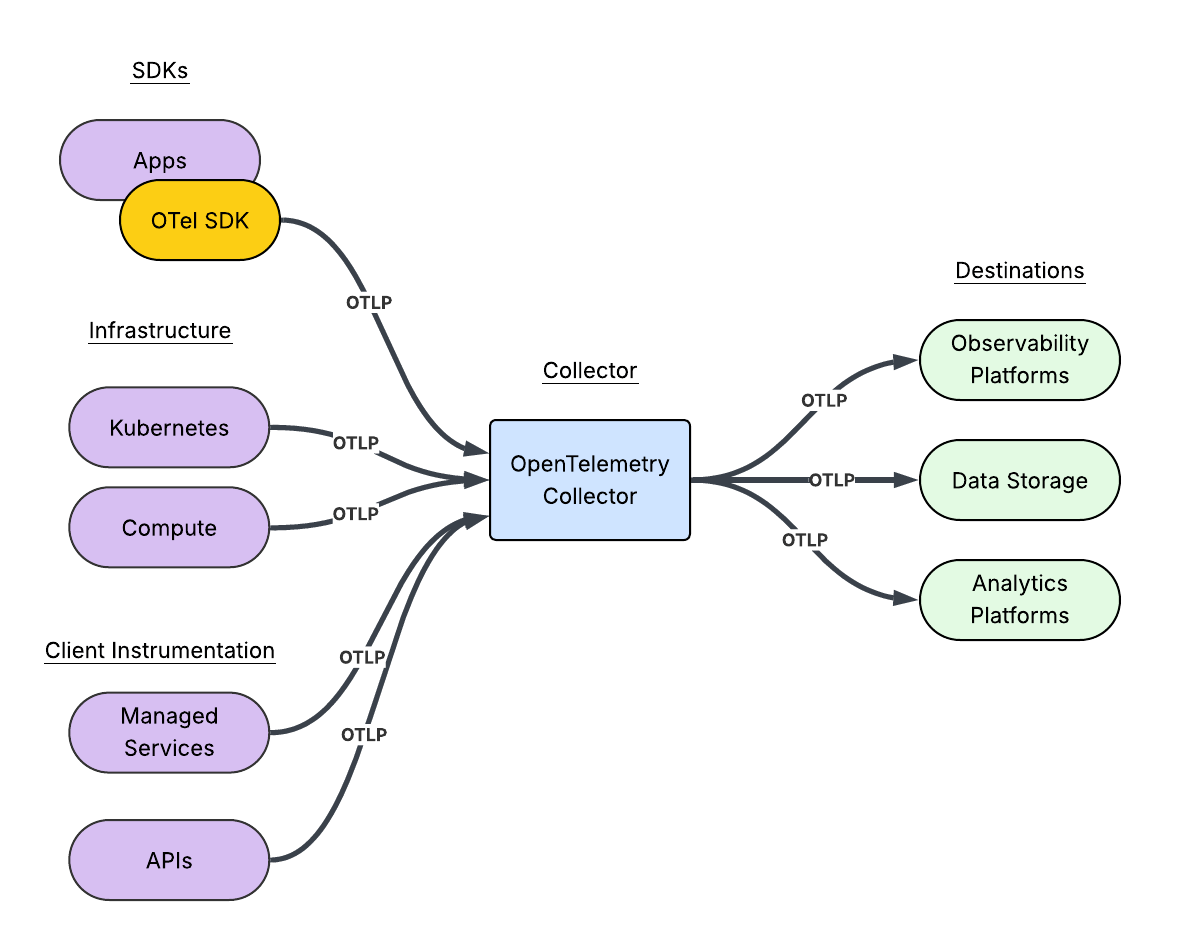
Heroku recently made the next generation platform – Fir – generally available. Fir builds on the strengths of the Cedar generation while introducing a new modern era of developer experience. Fir leverages modern cloud-native technologies to provide a seamless and performant platform. One of the goals we set out to achieve with Fir is to […] The post OpenTelemetry Basics…
1 May 2025
We’re excited to announce the release of Heroku-Streamlit, a template that makes deploying interactive data visualization applications on Heroku simpler than ever before. Streamlit is an open-source app framework built for machine learning and data science projects. This Streamlit App brings together Heroku’s scalable cloud platform and Streamlit’s intuitive Python-based data application framework. Whether you’re […] The post Introducing Heroku-Streamlit:…
2 Apr 2025
We’re excited to introduce Heroku-Jupyter, an open-source, production-ready solution for running Jupyter Notebooks on Heroku with persistent storage, seamless deployment, and built-in security. Whether you’re a data scientist, educator, or developer, you can now spin up a cloud-based Jupyter environment in minutes. Why Jupyter on Heroku? Jupyter Notebooks provide an interactive computing environment ideal for […] The post Jupyter Notebooks…
4 Mar 2025
Developers love Heroku for its elegance and simplicity to easily build and deploy any type of app or service in the languages they love. This flexibility enables developers to build robust custom applications or specialized capabilities like agent actions, complex pricing calculations, or real-time transformations and processing. These are often capabilities where Salesforce Admins and […] The post Heroku AppLink…
10 May 2024

Heroku Postgres is one of the world’s largest managed data stores. Our customers rely on Heroku Postgres to store valuable data, which powers a range of experiences and services they build on Heroku. Salesforce Data Cloud integrates all your company’s data into the Einstein 1 Platform, creating a comprehensive customer view for personalized engagements, analytics, […] The post Introducing the…
12 Jan 2022
Ryan Basayne of Coralogix sits down with Morgan Shultz of Copado to discuss his experience leveraging Coralogix on the Heroku Platform. Copado is an end-to-end, native DevOps solution that unites Admins, Architects and Developers on one platform. DevOps is a team sport, and uniting all 3 allows you to focus on what you need to […] The post How Copado…
21 Jan 2021

The Xplenty (Integrate.io) platform allows organizations to integrate, process, and prepare data for analytics in the cloud. Xplenty is also available as a Heroku Add-on. Abe Dearmer is the company’s COO. Often, innovation sparks innovation in unforeseen ways. In the early 1950’s, television brought the world an entirely new experience that not only changed people’s […] The post An Iconic…
11 Dec 2020

This post previously appeared on the Salesforce Architects blog. Event-driven application architectures have proven to be effective for implementing enterprise solutions using loosely coupled services that interact by exchanging asynchronous events. Salesforce enables event-driven architectures (EDAs) with Platform Events and Change Data Capture (CDC) events as well as triggers and Apex callouts, which makes the […] The post Extend Flows…
8 Oct 2020
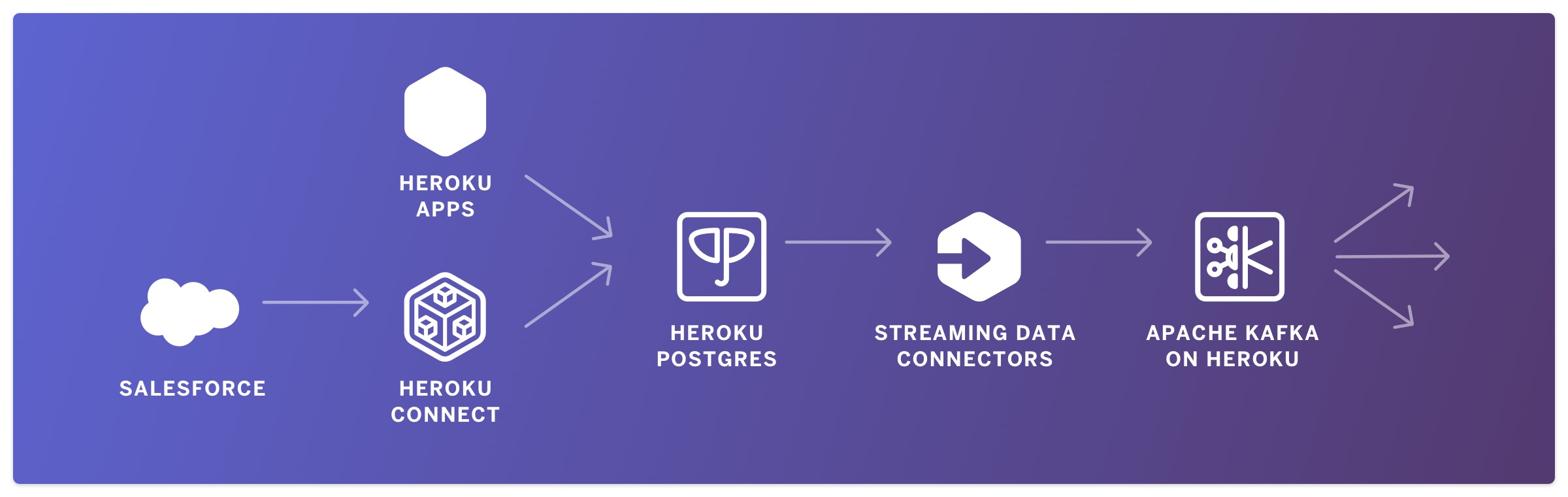
This summer, we announced the beta release of our new streaming data connectors between Heroku Postgres and Apache Kafka on Heroku. These connectors make Change Data Capture (CDC) possible on Heroku with minimal effort. Anyone with a Private or Shield Space, as well as a Postgres and an Apache Kafka add-on in that space, can […] The post Heroku Streaming…
10 Jul 2020
Today we are announcing a beta release of our new streaming data connector between Heroku Postgres and Apache Kafka on Heroku. Heroku runs millions of Postgres services and tens of thousands of Apache Kafka services, and we increasingly see developers choosing to start with Apache Kafka as the foundation of their data architecture. But for […] The post Streaming Data…
16 Apr 2019

The data we store holds value, but refining data into meaning remains a difficult task. Over the last few months, we’ve taken a step back to figure out what we can do to help our users cross that divide, and rebuilt Heroku Dataclips from scratch with that goal in mind. The result is an experience […] The post A Dialog…
28 Feb 2019

The recent introduction of Platform Events and Change Data Capture (CDC) in Salesforce has launched us into a new age of integration capabilities. Today, it's possible to develop custom apps that respond to activity in Salesforce. Whether you're creating a memorable customer interaction or implementing an internal workflow for employees, consider an event-sourced design to […] The post Reactive Programming…
6 Dec 2018
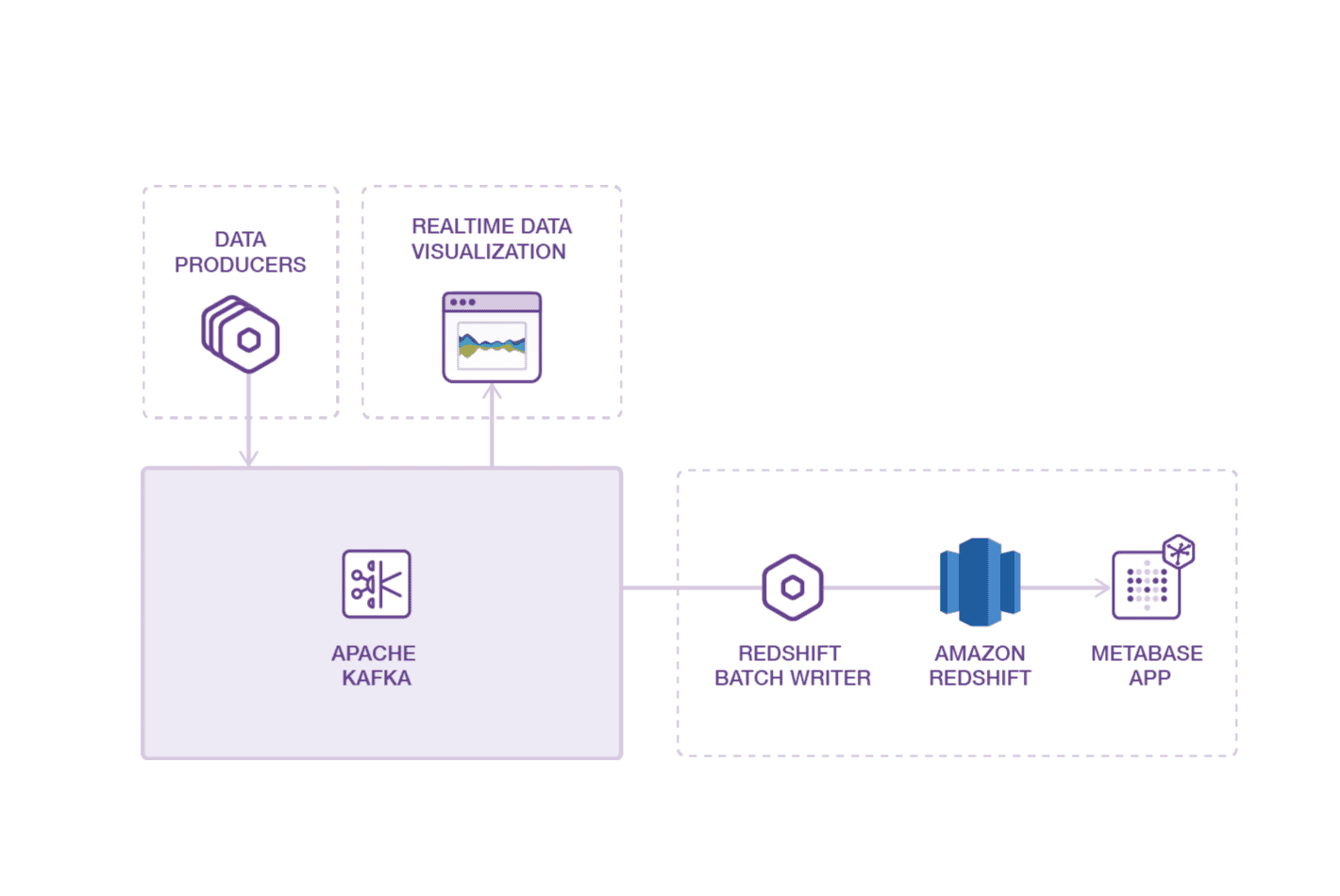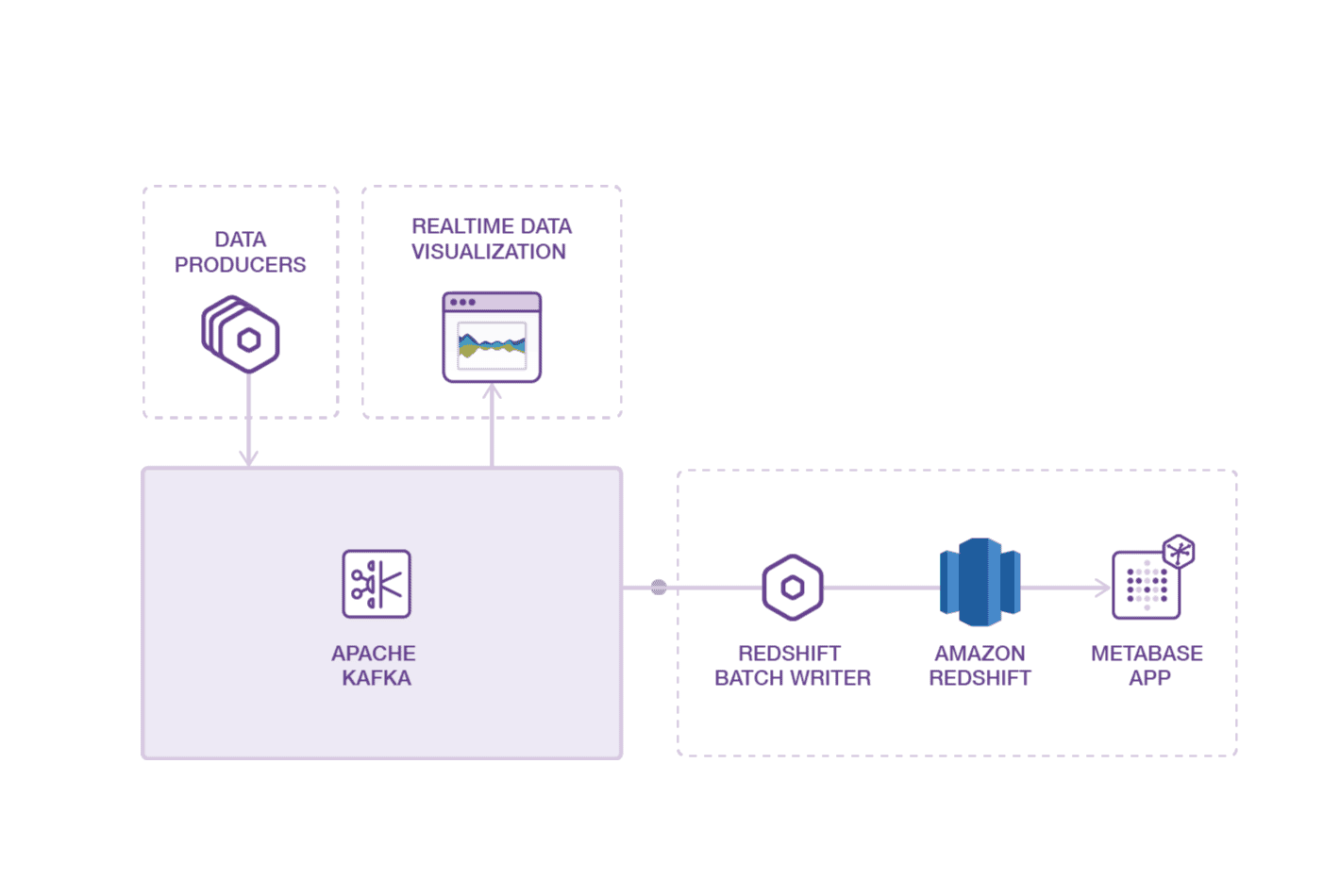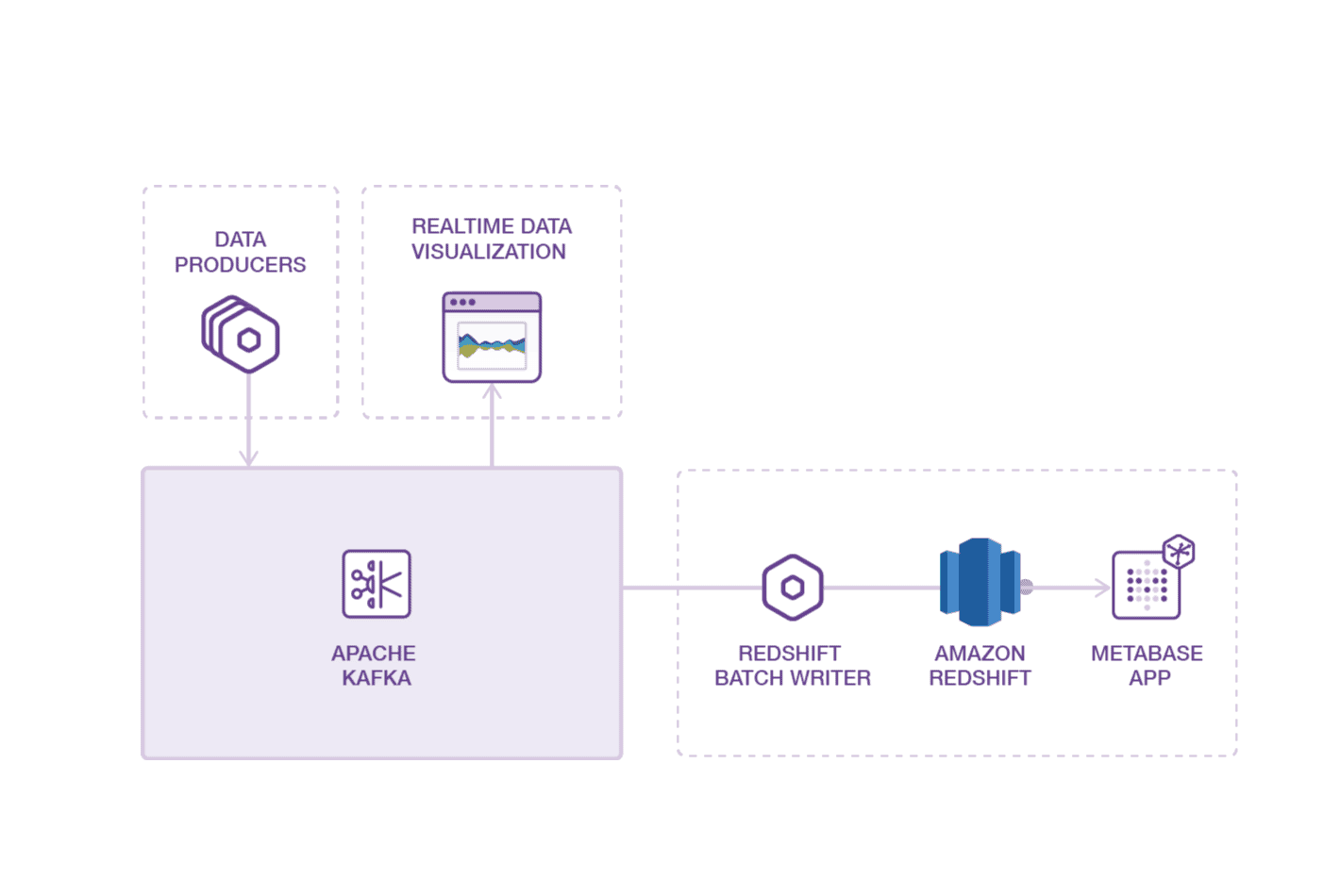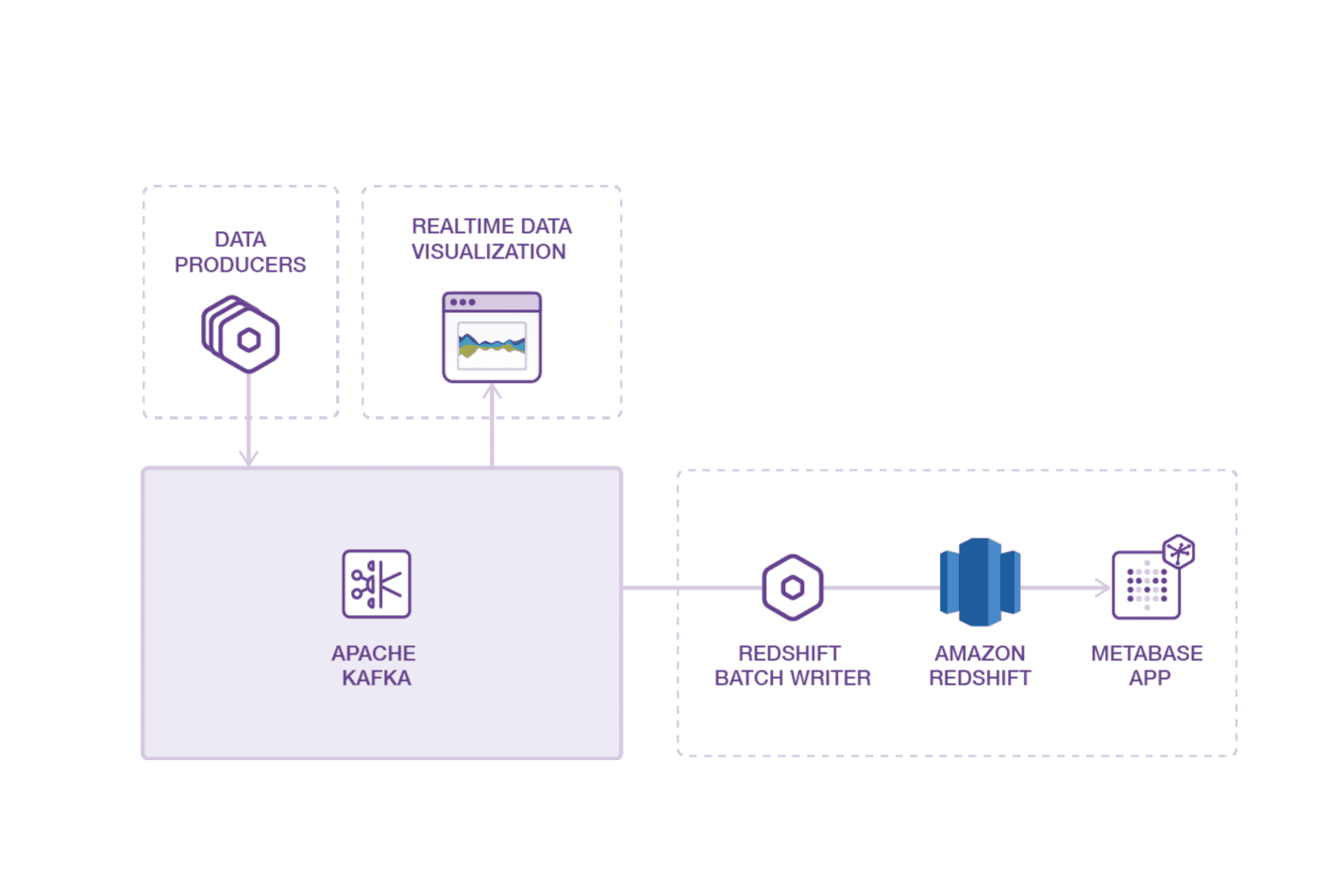
Building a SaaS product, a system to handle sensor data from an internet-connected thermostat or car, or an e-commerce store often requires handling a large stream of product usage data, or events. Managing event streams lets you view, in near real-time, how users are interacting with your SaaS app or the products on your e-commerce […] The post Manage Real-time…
14 Aug 2018
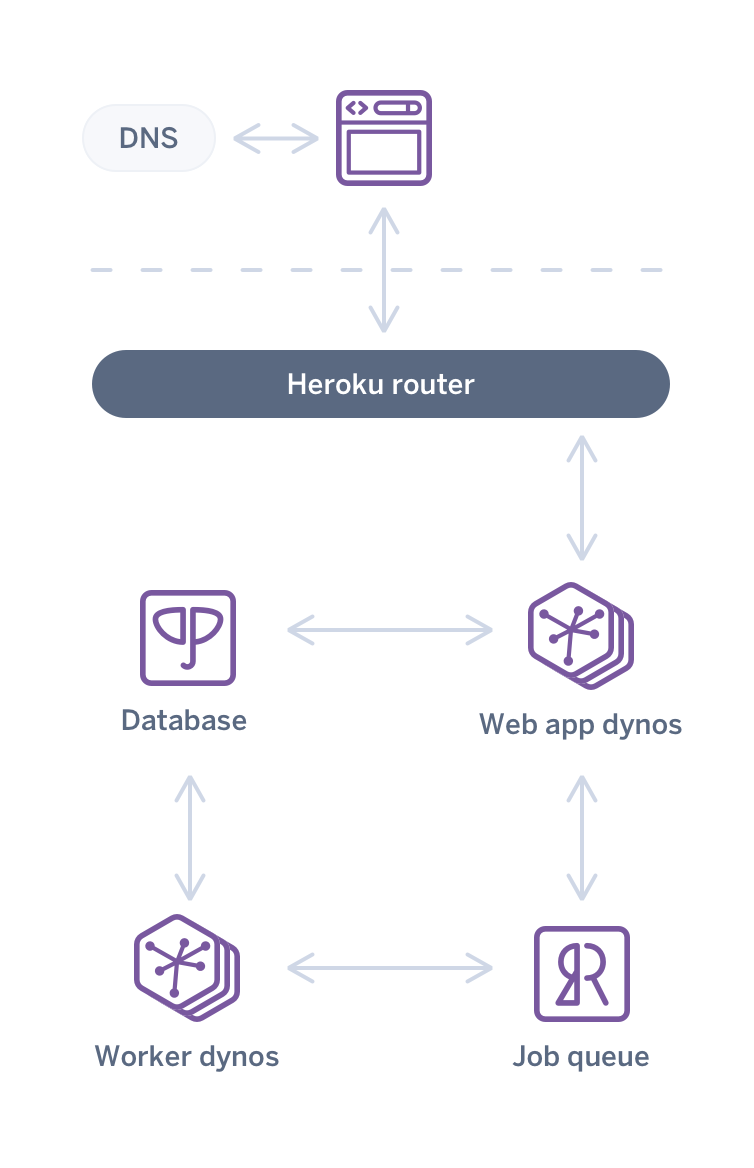
This is the first in a series of blog posts examining the evolution of web app architecture over the past 10 years. This post examines the forces that have driven the architectural changes and a high-level view of a new architecture. In future posts, we’ll zoom in to details of specific parts of the system. […] The post Beyond Web…
19 Dec 2017

Designing scalable, fault tolerant, and maintainable stream processing systems is not trivial. The Kafka Streams Java library paired with an Apache Kafka cluster simplifies the amount and complexity of the code you have to write for your stream processing system. Unlike other stream processing systems, Kafka Streams frees you from having to worry about building […] The post Kafka Streams…
14 Sept 2017
Event-driven architectures are on the rise, in response to fast-moving data and constellations of inter-connected systems. In order to support this trend, last year we released Apache Kafka on Heroku – a gracefully integrated, fully managed, and carefully optimized element of Heroku’s platform that is the culmination of years of experience of running many hundreds […] The post Kafka Everywhere:…
28 Sept 2016
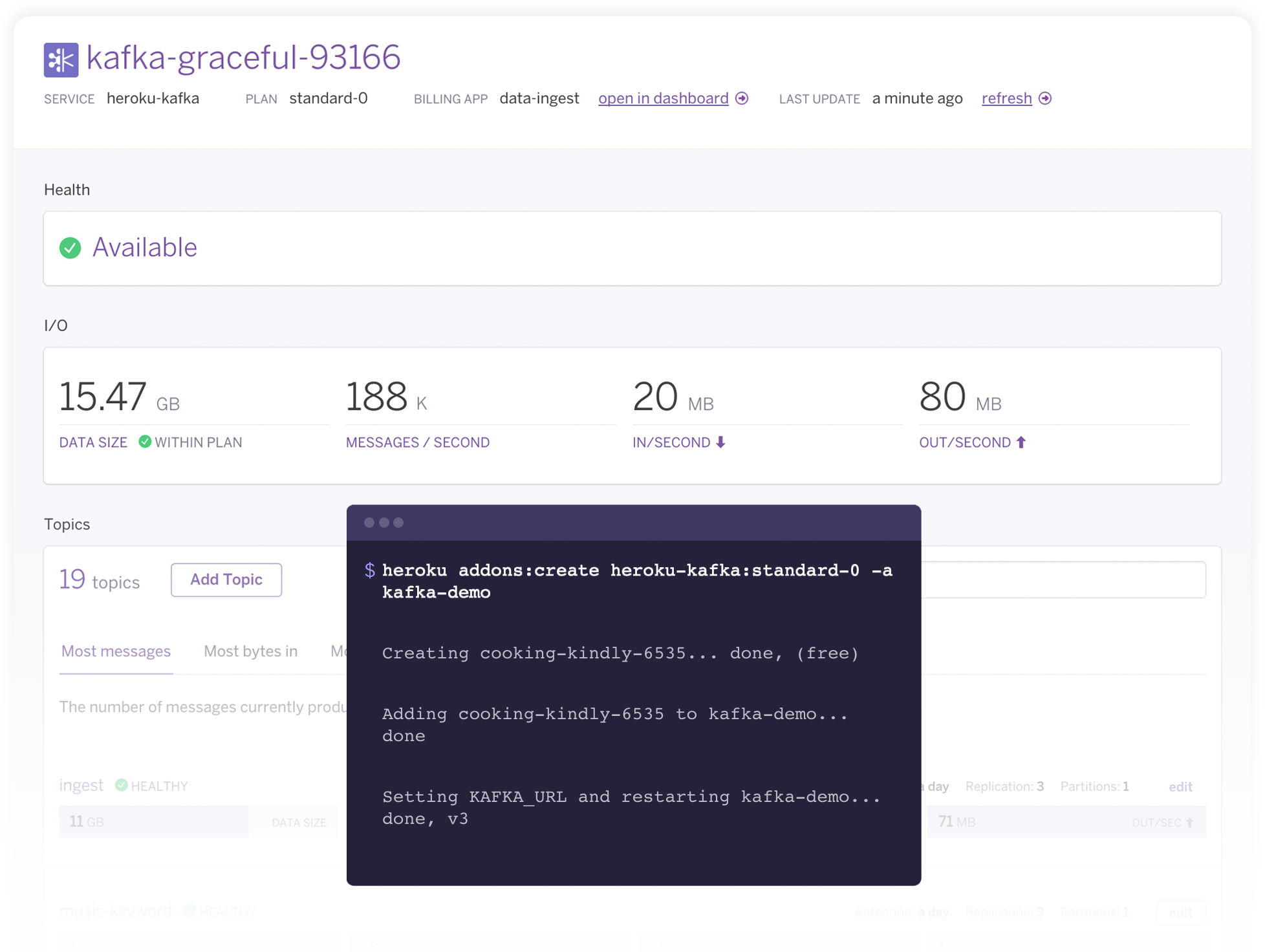
Many of the compelling and engaging application experiences we enjoy every day are powered by event-based systems; requesting a ride and watching its progress, communicating with a friend or large group in real time, or connecting our increasingly intelligent devices to our phones and each other. Behind the scenes, similar architectures let developers connect separate […] The post Apache Kafka…
26 May 2016

For almost two years now, the Heroku Dashboard has provided a metrics page to display information about memory usage and CPU load for all of the dynos running an application. Additionally, we’ve been providing aggregate error metrics, as well as metrics from the Heroku router about incoming requests: average and P95 response time, counts by […] The post Heroku Metrics…
5 Sept 2014
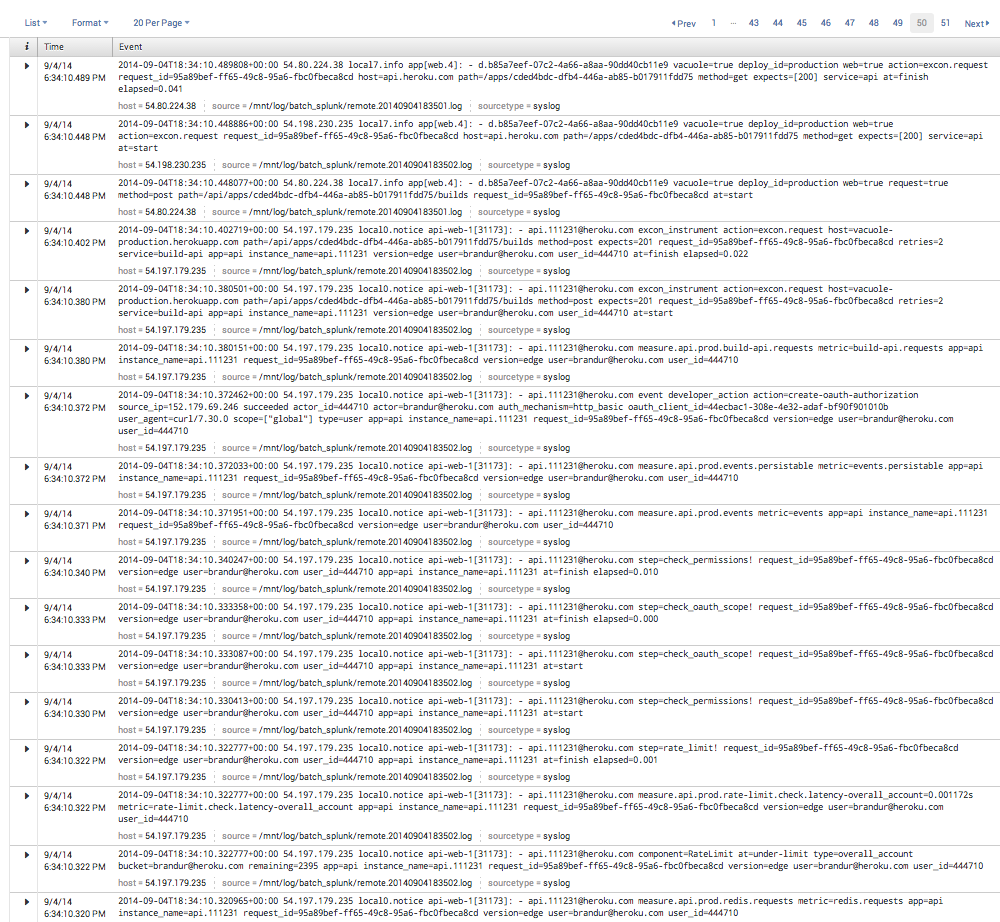
Many of Heroku's internal components make heavy use of logfmt to log information about what's going on in production. The format is hugely valuable in that it allows us to retroactively analyze what happened during any arbitrary request to our components, query our log traces in very flexible ways, and combined with Splunk, easily generate […] The post Hutils –…